We might want to have a little background on what discrete signals are, then we need to know what finite signals, infinite signals, recursive signals & its frequency are. Discrete signals are photographs of signals taken in certain time interval \(T_s\), with corresponding sampling frequency \(F_s = 1 / T_s\). These signals can have a frequency \(f\) with which it is repeating. Say, if \(M\) samples for one unique sequence, then \(f = 1 / M T_s\) or \(f = F_s / M\).
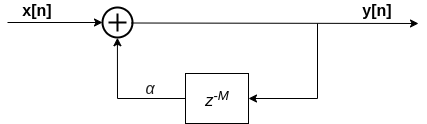
Let us take a look at the feedback system:
In the above diagram, we see that the input is taken as it is and added to delayed output signal. The delay unit \(z^{-M}\) acts as a memory cell, which stores \(M\) signals before it outputs back the first signal. This unit is a FIFO, i.e, the first signal stored in this unit will be the first to be sent out. Then we have the scaling factor \(\alpha\), which will scale the output of the delay unit. Generally, this would be lesser than to 1, to give the damping effect.
Here, we can observe that, to generate periodic signals, we have to set the delay \(M\) to be equal to the number of samples in the input signal \(x[n]\).
Now let us take a finite signal \(x[n]\) which has \(M\) samples as input to our feedback system and generate the output periodic signal with the input as constituent. The generated output signal would be a note with frequency \(F\). Best input for the Karplus-Strong algorithm would be a random signal.
We set the sampling frequency which will later be used to play audio.
Fs=16000# 16 KHz sampling rate
The above sampling frequency means that, there would be 16000 samples of data per second.
In Karplus-Strong (K-S) Algorithm, the period of the output signal is the length of the input finite signal. Say, if we have 50 samples in the input signal, then frequecy will be \(f = F_s / M\), i.e, 16000/50, which would be \(320 Hz\).
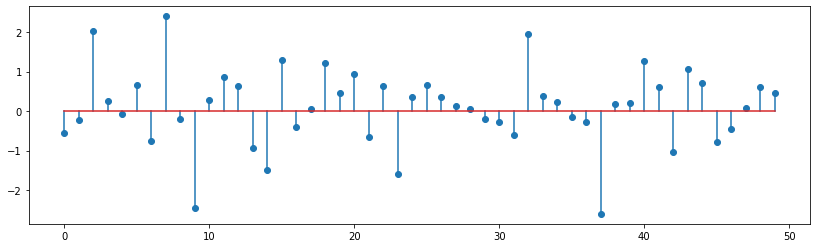
Now let us choose an input signal with random values.
x_n=np.random.randn(50)plt.stem(x_n);
Now let us define a function which returns output signal generated using K-S algorithm. Here we define the total number of output data points, as in theory, K-S algorithm generates infinite signal.
Here, \(y2\) is a higher pitched note as the frequency \(f = F_s / 10\) is higher than that of \(y1\) which is \(f = F_s / 50\). And we observe the decay is quite fast in \(y2\). As, this is not good, let us compensate for this by changing \(\alpha\). We shall adjust alpha so that all the notes have a decay comparable to that of buffer length of 50. This way the decay timing would match for all the signals.
Here we are essentially replacing the denominator of power of \(\alpha\) in the equation with fixed length by multiplying the actual length of the buffer and then dividing by the fixed length, and thereby replacing the denominator.
Now let us play chords. In the tutorial on coursera, we are presented with opening chord of “A Hard Day’s Night”, by The Beatles.
We use limited notes \(D_3, F_3, G_3, F_4, A_4, C_5, G_5\) and \(D_2\). In western music, we have the reference note \(A_4\) with frequency of \(440 Hz\), and other notes are calculated by the formula: \(f(n) = A_4 \times 2^{n/12}\), where \(n\) is the number of half-tones between \(A_4\) and the desired note. The exponent \(n\) will be positive if the note is above \(A_4\), else \(n\) is negative.
Here, we generate each note using Karplus-Strong Algorithm, and we provide different gains to each note to mix “different” instruments.
deffreq(note):# general purpose function to convert a note in standard notation
# to corresponding frequency
iflen(note)<2orlen(note)>3or \
note[0]<'A'ornote[0]>'G':return0iflen(note)==3:ifnote[1]=='b':acc=-1elifnote[1]=='#':acc=1else:return0octave=int(note[2])else:acc=0octave=int(note[1])SEMITONES={'A':0,'B':2,'C':-9,'D':-7,'E':-5,'F':-4,'G':-2}n=12*(octave-4)+SEMITONES[note[0]]+accf=440*(2**(float(n)/12.0))#print note, f
returnf
defks_chord(chord,N,alpha):y=np.zeros(N)# the chord is a dictionary: pitch => gain
fornote,gaininchord.iteFms():# We calculate the number of samples in intial buffer, M = Fs/f
M=int(np.round(float(Fs)/freq(note)))# create an initial random-filled KS buffer the note
x=np.random.randn(M)y=y+gain*KS(x,N,alpha)returny
# A Hard Day's Night's chord
hdn_chord={'D2':2.2,'D3':3.0,'F3':1.0,'G3':3.2,'F4':1.0,'A4':1.0,'C5':1.0,'G5':3.5,}IPython.display.Audio(ks_chord(hdn_chord,Fs*4,0.995),rate=Fs)
Final Quiz
Analysing the following cell to understand what exactly is happening.
In the above cell, we see that we are adding two notes of different pitch, but matching in the length, as we take four copies of 100-sample note and five copies of 80-sample note. Then we apply K-S algorithm on the final buffer of length 400, and also the \(\alpha\) is 1. So, the output signal will actually be mixture of two frequecies characterized by 100-sample note and 80-sample note. Even though the initial buffer provided to K-S algorithm is of length 400, the underlying notes characterize the output signal, as their periodicity is not tampered.
We can prove it by calculating K-S output signals for each of the notes and then adding them to find same sound as before.
Understanding linear algebra has never been this easy as watching and learning from 3blue1brown. The YouTube series is just perfect with its superb animations which helps one build intuition.
Vectors are basically line drawn from origin to a point in the coordinate system. One needs to understand what basis of a coordinate system is and how the change of basis affects the vectors. Then we need learn that matrix multiplication with a vector is basically linear transformation of the vector. One could also say that, the final vector of this transformation is the vector in current coordinate system, if the initial vector was the vector defined in the coordinate system defined by the linear transformation matrix. Here we can take the columns of the matrix as basis of the other coordinate system.
Basic properties of linear transformation:
\[\begin{aligned}
L (\vec{v} + \vec{w}) &= L (\vec{v}) + L(\vec{w}) \\
L (c\vec{v}) &= cL(\vec{v}) \\
\end{aligned}\]
Determinants basically give us the area of the parallelogram formed by the two vectors derived from columns of the matrix ( \(2D\) square matrix). If we have two vectors and their area \(A\), and we transform this using a matrix \(M\), then the area of the two vectors are scaled by \(det(M)\), i.e, the area of the transformed vectors would be \(det(M) * A\).
This concept for \(2D\) matrix can be extended to \(3D\), where the determinant would give out the volume of the parallelopiped. The scaling explained above would apply here also.
Since determinant gives the area, if the area is zero, that means the vector will be squished to a lower dimension.
Eigen Values & Vectors
Suppose you transform a vector and it stays in the same line, i.e, the direction will stay same or opposite, and the length may increase or decrease. Then that vector is an eigen vector. The line of the vector is not shaken off.
\[A \vec{v} = \lambda\vec{v}\]
Here \(\lambda\) is the scaling factor which is also called eigen value.
How to calculate
Now that we have the definition, let us see the steps to derive the eigen vectors and eigen values.
First let us convert the R.H.S to be matrix-vector multiplication instead of scalar-vector multiplication.
\[A \vec{v} = \lambda I\vec{v}\]
Now that both the sides are similar, let us shift the R.H.S to the left.
\[\begin{aligned}
A \vec{v} - \lambda I\vec{v} &= \vec{0} \\
(A - \lambda I)\vec{v} &= \vec{0}
\end{aligned}\]
Since, the vector stays in the same line, if the transform \((A - \lambda I)\) has the vector to land on the origin, then the determinant of this transform has to be zero, then the vector on its line will be squished to the origin, since it won’t be shaken off its line. So, the determinant of the transform should be zero.
Why I am stressing the part where the eigen vector will be squished to origin is because, if it was any other vectors not on the line of eigen vectors, then they would perhaps be squished to \(1D\) but not on to origin, they could have value other than zero on the \(1D\) line. So, for thos vectors to be squished to the origin, the transform vector has to be \(zero\) \(matrix\)
Finally, we need to solve for \(\lambda\)
$$det (A - \lambda I) = 0$$
\[\begin{aligned}
where,
A &= \left( \begin{array}{c}
a & b \\
c & d \\
\end{array} \right) \\
\lambda I &= \left( \begin{array}{c}
\lambda & 0 \\
0 & \lambda
\end{array} \right) \\
\end{aligned}\]
So,
\[\begin{aligned}
det (A - \lambda I) &= 0 \\
det\left( \begin{array}{c}
a - \lambda & b \\
c & d - \lambda \\
\end{array} \right) &= 0 \\
(a - \lambda)(d - \lambda) -bc &= 0 \\
\end{aligned}\]
Solving the above equation we get the eigen values, which we use to get the eigen vector(s) \(\vec{v}\). Remember that if we do not get a real solution for \(\lambda\), then there are no eigen vectors in the real plane.
Sometimes we could also get only a single eigen vector, for example, shear transform \(\left( \begin{array}{c}1 & 1 \\0 & 1 \\ \end{array} \right)\).
Sometimes we can also get infinite number of eigen vectors, for example, \(\left( \begin{array}{c}3 & 0 \\0 & 3 \\ \end{array} \right)\), here the all the vectors are scaled by \(3\).
Sometimes we could also not get any eigen vector, for example, roatation by \(90^o\) transform \(\left( \begin{array}{c}0 & 1 \\-1 & 0 \\ \end{array} \right)\).
Applications
Eigen Decompostition or Diagonalisation
Say the transformation matrix is a diagonal matrix, i.e, all the elements except diagonal elements are zero, then we can conclude that the basis are eigen vectors and the values of diagonal elements are the eigen values corresponding to those eigen vectors. Important take here is that, the transformation does not change the line of the basis vectors, which make them eigen vectors also.
So, if say we have a transformation matrix that is not diagonal, we can choose the basis vectors such a way that these basis vectors do not change their line after the transformation. And, we know that eigen vectors are the vectors that do not change direction when applied transformation. So, if we shift our basis to these eigen vectors, the corresponding transformation matrix in this new coordinate system formed by these basis will be diagonal matrix, as it would just stretch the basis(eigen) vectors, and not change its direction. But not all transformation matrix can have eigen vectors enough to span all the vectors. We saw that shear transform has only one eigen vector, due to which we cannot apply the above technique to diagonalise the matrix.
When we change the basis, the new transformation is defined by \(A^{-1} M A\), where \(M\) is the transformation matrix in current coordinate system and \(A\) is the matrix formed by the new basis in the order, where \(x\) and \(y\) are transformed.
Since, the transformation on the eigen vectors used as basis will always have the eigen vectors in line but stretched by their corresponding eigen values, the new transformation matrix will be diagonal matrix with eigen values as diagonal elements.
Why is diagonal matrix so important? Because if you multiply a diagonal matrix by itself, and continue multiplying, we can generalise the final matrix based on the starting matrix. Example:
\[\left( \begin{array}{c} a & 0 \\ 0 & d \\ \end{array} \right) \left( \begin{array}{c} a & 0 \\ 0 & d \\ \end{array} \right) = \left( \begin{array}{c} a^2 & 0 \\ 0 & d^2 \\ \end{array} \right) \\\]
So, if \(A\) is a diagonal matrix, \(A^n\) is simply the diagonal elements raised to the power of \(n\). Because of this we use eigen decomposition to calculate the diagonal matrix for a given transformation matrix \(M\). If \(D\) is the diagonal matrix, then \(M = A D A^{-1}\), where \(A\) is the matrix formed by the eigen vectors.
The regex finds the two expressions, where both start with a comma and the second one ends with end of line. This is replaced with the first expression only. The goal was to remove the second expression. Here, the old list will be untouched.
\1 suggests the first regex.
Background
I had created a list for my deep-learning model training. This was basically a multi-task training. I was fiddling between two-task training and single-task training, that’s when I came across an errand to modify the list used in two-task training to the one to be used in single-task training. Each line of my list basically consisted of image path and label numbers of each of the tasks separated with commas. I wanted to remove the second task’s labels, which is the last column.
1. Download the javascripts required to enable anchors
Download the latest release from this Git repo. Just copy the anchor.min.js file into public/css/ path. Then download the jQuery script from their official website. Download the compressed production version. Copy this script to public/css/ path as well.
2. Adding the scipt to post.html
Just add the following codeblock at the start of _layouts/post.html and you are done.